When we first released Terminal-Bench, agents struggled to reliably complete tasks involving small programs. Since then, agents have made tremendous progress and can now complete large-scale projects autonomously. This progress is exciting, and we felt another flavor of benchmark was needed to test this capability.
Today we introduce Terminal-Bench Challenges, which are long-horizon, token-intensive, single-task benchmarks. Solving a challenge is a significant accomplishment that would have taken a team of experts months of work.
Browse the Terminal-Bench Challenges or the challenge leaderboards.
| SWE-bench | Terminal-Bench | Terminal-Bench Challenges | |
|---|---|---|---|
| Task type | Patch a single issue | Write and execute small programs and CLI commands | Build an entire codebase from scratch |
| Time per task | minutes to hours | minutes to hours | days |
| Cost per task | ~$1 - $10 | ~$1 - $100 | ~$1k+ |
| Solution LOC | up to 500 lines | up to 10k lines | ~10k-500k |
As a starting point for this new format, we are releasing three challenges. Each challenge is composed of a concise project description and an extensive test bed, both of which are provided to the agent at the start of the task.
The agent must autonomously complete the project end-to-end without intervention. There are no time or resource limits. Outputs will be graded along the task-specific metric, which can include correctness and performance.
Rust Compiler Speedup
Rust compilation speed has long been a frustration the broader community has faced. The open source community has made significant improvements: adding parallelism to the frontend, introducing incremental compilation, and optimizations on top of LLVM. However, space for structural changes still exists in order to reduce compilation time. Large improvements would require restructuring the codebase and solving notorious problems with parallelization, linking, and codegen bloat.
Hillclimbing this task would affect thousands of Rust developers. We designed the testbed as a miniature version of Rust's production compiler testbed: we verify correctness and grade compile time by measuring instruction count on a subset of 52 crates used in the official rustc-perf benchmark. After leaving Claude Code with Opus 4.8 to run for 12 hours, the agent was unable to make any significant improvement, with the optimization attempts leading to regressions.
Inference Engine Codegolf
Implement an inference engine in a single C/CUDA file under 25 kb to be able to serve Kimi 2.5. Our testbed measures performance on a Pareto frontier (TTFT, tokens/s, TPOT).
Inspired by the TB2 task gpt2-codegolf, this task extends it to the next level: serving a real frontier-sized model with modern architectural complexities and inference optimizations while trying to minify the code.
We ran experiments letting Claude Code with Opus 4.8 attempt this task for 12 hours, in which the agent spent the time improving a mismatch in logprobs with the reference SGLang engine, getting close, but unable to match the correctness gate in under 25 kb and not attempting any performance techniques.
WASM WebGL Renderer
Build a software-based graphics renderer entirely in JavaScript/WebAssembly that can run WebGL programs (3D graphics) without needing a browser or a GPU. A correct implementation is a zero-dependency drop-in replacement for headless-gl: any Node.js project can npm install it and get a working WebGL context without C++ bindings, Chromium, or a GPU.
Solving this would unlock server-side 3D rendering on edge/serverless platforms (Cloudflare Workers, Vercel Edge, Lambda) where native binaries can't run, and deterministic visual regression testing in CI without managing Chromium + SwiftShader + Xvfb.
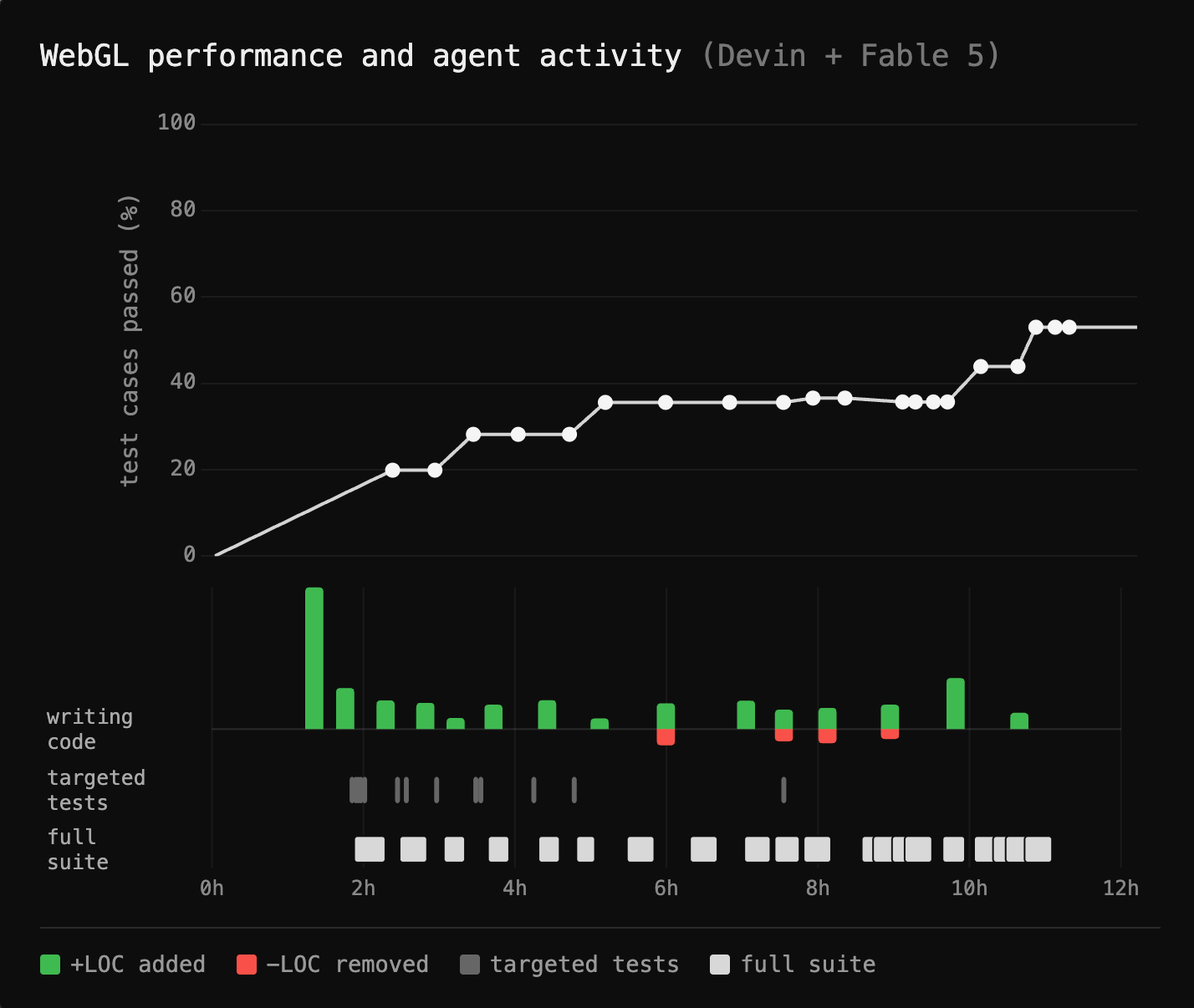
In initial experiments, after 12 hours, agents (Devin with Opus 4.8 and Fable 5) are able to pass about half of the test cases required to solve the WebGL task. Devin with Fable 5 was successful in achieving 96.4% test coverage on WebGL 1.0, but struggled to make progress on the harder WebGL 2.0 conformance tests (20.5%).
Throughout testing, agents struggled to work efficiently. We noticed two particular failure modes.
Lack of exploration in solution space: Agents have trouble making forward progress after some time and are unwilling to delete large chunks of the codebase and explore large scale changes in the solution space.
Test suite overuse: Agents will happily kick off the full test suite, which can take well over 20 minutes, when a handful of targeted tests covering its current change would do. The correct behavior instead should be the agent writing its own testing suite targeting the changes it's working on.
Submissions
Unlike our previous Terminal-Bench evaluations, we do not provide restrictions on the agent environment (CPU, memory, storage, state, system, etc.) or the agent (no timeouts, etc.). We package Terminal-Bench Challenges in the Harbor task format for standardization and convenience. We are excited to see a diversity of approaches to tackling Challenges, including multi-agent systems.
To submit a solution to a Challenge leaderboard, share a repository that contains the final output artifact and full agent logs. The artifact must pass the verification suite and the logs must demonstrate that no additional guidance or code was provided by humans. Challenges should be solved fully autonomously given the instruction and input, without task-specific guidance.
Conclusion
As agents work independently for longer, the tools we use to evaluate agents need to expand. The three Challenges we release today are a step towards that goal. Each is a single-task benchmark that requires agents to complete large projects autonomously, managing vast numbers of actions, context, and code. Solving a challenge is a milestone accomplishment in the progress of agents.
Alongside Terminal-Bench Challenges, the existing Terminal-Bench format will remain a useful tool (Terminal-Bench 3.0 is in development) to provide rich signal quickly on a broader distribution of agent capabilities. We view these two formats as complementary in understanding agents' capabilities. There is also an opportunity to compress core difficulties found in long-running workflows into smaller, cheaper to evaluate tasks.
We thank Modal and Cognition for supporting this project. If you are interested in developing further challenges, join our Discord and the #tb-challenges channel.
Written by
The Terminal-Bench Team (TB Challenges Lead: Andrew Wang)